Tutorial 3: Parameters¶
In this third tutorial, we're going to focus on the structure and contents of the data represented by the parameters
dictionary attribute of CadetCareerProblem.
# Import "Random_1" instance
instance = CadetCareerProblem('Random_1')
💻 Console Output
Importing 'Random_1' instance...
Instance 'Random_1' initialized.
With this line, we now have a working problem instance. This "instance" object has many attributes and methods defined that we can access. The "parameters" of the instance are represented by a dictionary, which is an attribute of the instance object. Various parameters are loaded in as numpy arrays within that dictionary. These are the "fixed" parameters, and contain different characteristics of this particular dataset. I call them "fixed" parameters because these are the attributes of the problem that the analyst does not have much, if any, control over (the characteristics of the cadets and AFSCs themselves). Let's first discuss the two "primary" datasets: "Cadets.csv" and "AFSCs.csv".
1. Cadets¶
"Random_1 Cadets.csv" defines the basic features of the cadets in this problem instance. It looks like this:
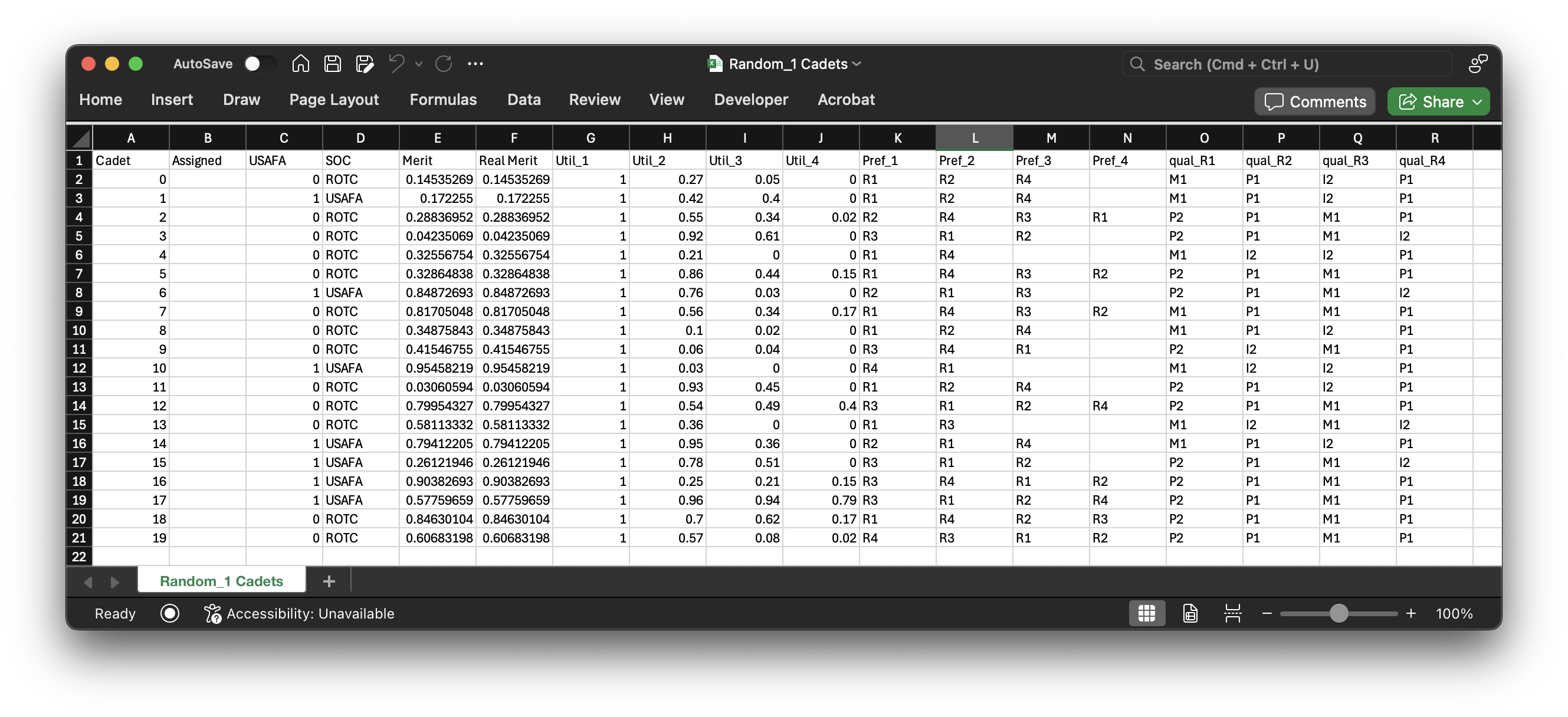
We can gain quite a bit of information from this dataset. I will reiterate that data is represented in this module as
numpy arrays within certain dictionaries. I extract these arrays from excel using pandas as the dataframe vehicle. This
data processing step occurs in the
import_cadets_data() function, which is called
from within the __init__ method of CadetCareerProblem.
Let's go through some of these arrays.
# Cadet identifier
print("'cadets':", instance.parameters['cadets'])
# Binary USAFA array
print("'usafa':", instance.parameters['usafa'])
# Source of Commissioning array
print("'soc':", instance.parameters['soc'])
💻 Console Output
'cadets': [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
'usafa': [0 1 0 0 0 0 1 0 0 0 1 0 0 0 1 1 1 1 0 0]
'soc': ['ROTC' 'USAFA' 'ROTC' 'ROTC' 'ROTC' 'ROTC' 'USAFA' 'ROTC' 'ROTC' 'ROTC'
'USAFA' 'ROTC' 'ROTC' 'ROTC' 'USAFA' 'USAFA' 'USAFA' 'USAFA' 'ROTC'
'ROTC']
You'll notice the parameters attribute of the CadetCareerProblem "instance" displayed above contains the data
from this csv. I've found dictionaries are quite flexible because they can contain a wide array of
information all in one place. They're also nice because the keys can be any string, allowing me to use superscripts "^"
and distinguish those from underscores "_". Numpy arrays are also very efficient with their fancy indexing and native
matrix operations. All throughout afccp, my standard is to use dictionaries containing numpy arrays.
There are two arrays containing order of merit percentile data. This is because this module used to simply be used for the Non-Rated line. In the NRL process, we re-scaled OM so that it averaged to about 0.50 since the Rated and USSF cadets were not in the mix. This creates two separate OM arrays: the re-sorted OM (merit) and the "real" OM where the cadets ranked among their entire class (merit_all).
print("'Real' Merit:", instance.parameters['merit_all'])
print("'NRL only' Merit:", instance.parameters['merit'])
💻 Console Output
'Real' Merit: [0.14535269 0.172255 0.28836952 0.04235069 0.32556754 0.32864838 0.84872693 0.81705048 0.34875843
0.41546755 0.95458219 0.03060594 0.79954327 0.58113332 0.79412205 0.26121946 0.90382693 0.57759659
0.84630104 0.60683198]
'NRL only' Merit: [0.14535269 0.172255 0.28836952 0.04235069 0.32556754 0.32864838
0.84872693 0.81705048 0.34875843 0.41546755 0.95458219 0.03060594
0.79954327 0.58113332 0.79412205 0.26121946 0.90382693 0.57759659
0.84630104 0.60683198]
You won't see a difference above because this data was generated and I didn't really see a need to differentiate it. Additionally, since AFPC/DSYA is now tasked with matching all cadets (not just NRL), there likely won't need to be a designation in the future, so we may go back to just one "Merit" column.
The "Assigned" column contains the AFSCs that may be fixed for certain cadets. Perhaps some cadets were rolled over from the previous AFSC and had already been awarded an AFSC. In those cases, we want to count them within our calculations but don't want to change their assigned AFSC. Again, since this is generated data, it does not play much of a role.
# Array of already awarded AFSCs for each of the cadets
instance.parameters['assigned'] # Empty array!
💻 Console Output
array([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan,
nan, nan, nan, nan, nan, nan, nan])
The "Util_1" -> "Util_4" columns indicate the "utilities" that the cadets have placed on their first, second, third, and fourth choice AFSCs. The "Pref_1" -> "Pref_4" columns indicate the ordered list of AFSC choices the cadets provided. Capturing the preference data in this manner (rows are cadets & columns are the choices) is the way we've always "initially" represented it. I will show later in the "Preferences" section that we can convert them into another useful representation of the data where the rows are still cadets but the columns are the AFSCs themselves.
# Utility cadet columns shown in numpy arrays
print('Cadet Utilities\n', instance.parameters['c_utilities'])
# Preference cadet columns shown in numpy arrays
print('\nCadet Preferences\n', instance.parameters['c_preferences'])
💻 Console Output
Cadet Utilities
[[1. 0.27 0.05 0. ]
[1. 0.42 0.4 0. ]
[1. 0.55 0.34 0.02]
[1. 0.92 0.61 0. ]
[1. 0.21 0. 0. ]
[1. 0.86 0.44 0.15]
[1. 0.76 0.03 0. ]
[1. 0.56 0.34 0.17]
[1. 0.1 0.02 0. ]
[1. 0.06 0.04 0. ]
[1. 0.03 0. 0. ]
[1. 0.93 0.45 0. ]
[1. 0.54 0.49 0.4 ]
[1. 0.36 0. 0. ]
[1. 0.95 0.36 0. ]
[1. 0.78 0.51 0. ]
[1. 0.25 0.21 0.15]
[1. 0.96 0.94 0.79]
[1. 0.7 0.62 0.17]
[1. 0.57 0.08 0.02]]
Cadet Preferences
[['R1' 'R2' 'R4' ' ']
['R1' 'R2' 'R4' ' ']
['R2' 'R4' 'R3' 'R1']
['R3' 'R1' 'R2' ' ']
['R1' 'R4' ' ' ' ']
['R1' 'R4' 'R3' 'R2']
['R2' 'R1' 'R3' ' ']
['R1' 'R4' 'R3' 'R2']
['R1' 'R2' 'R4' ' ']
['R3' 'R4' 'R1' ' ']
['R4' 'R1' ' ' ' ']
['R1' 'R2' 'R4' ' ']
['R3' 'R1' 'R2' 'R4']
['R1' 'R3' ' ' ' ']
['R2' 'R1' 'R4' ' ']
['R3' 'R1' 'R2' ' ']
['R3' 'R4' 'R1' 'R2']
['R3' 'R1' 'R2' 'R4']
['R1' 'R4' 'R2' 'R3']
['R4' 'R3' 'R1' 'R2']]
The last section of data contains the degree qualifications! Qualifications for AFSCs are currently determined by the Air Force Officer Classification Directory (AFOCD). Each AFSC provides a tiered list of degree groups (tiers 1, 2, 3, etc.) as well as a requirement level for that degree tier ("Mandatory", "Desired", "Permitted). In some cases, the AFSC also has an implied "Ineligible" tier. M, D, P, and I are the letters representing the four kinds of tiers shown in the qualification matrix below. The numbers correspond with the tier itself (1, 2, 3, ...).
instance.parameters['qual']
💻 Console Output
array([['M1', 'P1', 'I2', 'P1'],
['M1', 'P1', 'I2', 'P1'],
['P2', 'P1', 'M1', 'P1'],
['P2', 'P1', 'M1', 'I2'],
['M1', 'I2', 'I2', 'P1'],
['P2', 'P1', 'M1', 'P1'],
['P2', 'P1', 'M1', 'I2'],
['M1', 'P1', 'M1', 'P1'],
['M1', 'P1', 'I2', 'P1'],
['P2', 'I2', 'M1', 'P1'],
['M1', 'I2', 'I2', 'P1'],
['P2', 'P1', 'I2', 'P1'],
['P2', 'P1', 'M1', 'P1'],
['M1', 'I2', 'M1', 'I2'],
['M1', 'P1', 'I2', 'P1'],
['P2', 'P1', 'M1', 'I2'],
['P2', 'P1', 'M1', 'P1'],
['P2', 'P1', 'M1', 'P1'],
['P2', 'P1', 'M1', 'P1'],
['P2', 'P1', 'M1', 'P1']], dtype='<U2')
2. AFSCs¶
Like cadets, AFSCs are also defined in a separate csv file (Random_1 AFSCs.csv) which looks like this:
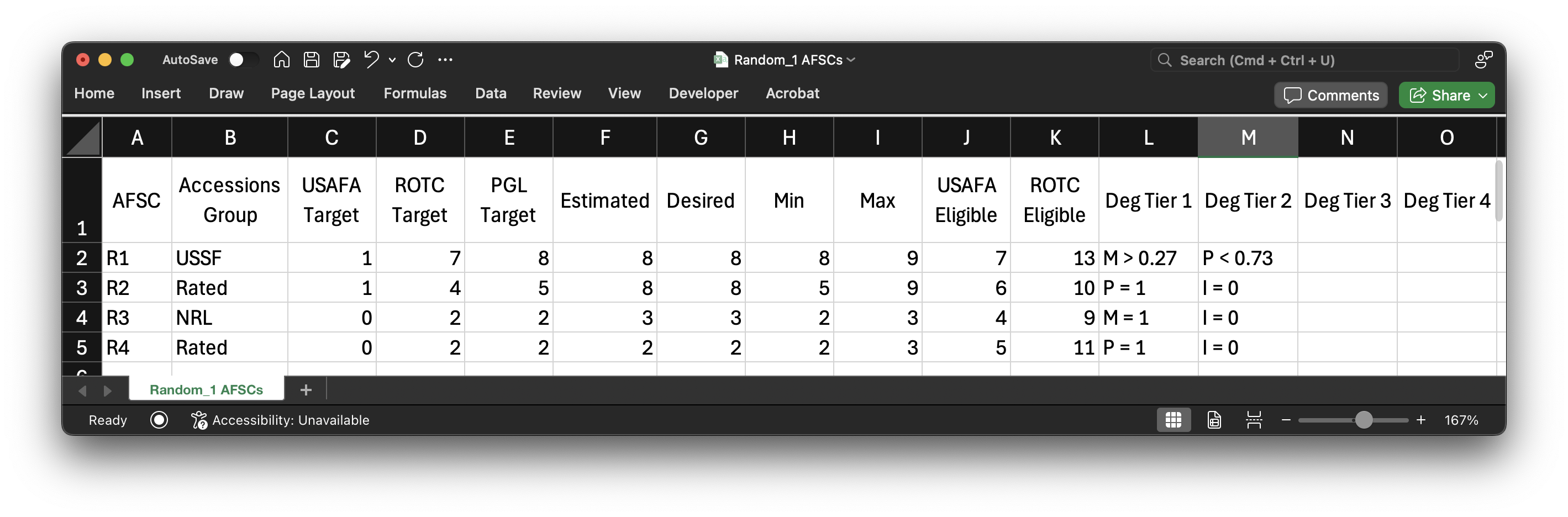
Here we have 4 AFSCs, and each has its own set of unique characteristics. In the same way as the cadets, this data is extracted from the import_afscs_data() function.
# Array of AFSC names
print(instance.parameters['afscs'])
💻 Console Output
['R1' 'R2' 'R3' 'R4' '*']
One thing to note is the extra AFSC "*". This represents the "unmatched" AFSC since we can have partial solutions where not all cadets go matched (think Rated) or in certain algorithms we may simply leave cadets unmatched. By allowing this extra AFSC at the end we can still evaluate these kinds of solutions. As a result, we do have certain parameters where we add a column at the end for this unmatched AFSC. One example is the cadet utility matrix below. For context, this matrix represents the same information captured in "c_utilities" only this time the columns are sorted by AFSC order, not the preference order.
# Utility matrix (cadet submitted)
print(instance.parameters['utility'])
💻 Console Output
[[1. 0.27 0. 0.05 0. ]
[1. 0.42 0. 0.4 0. ]
[0.02 1. 0.34 0.55 0. ]
[0.92 0.61 1. 0. 0. ]
[1. 0. 0. 0.21 0. ]
[1. 0.15 0.44 0.86 0. ]
[0.76 1. 0.03 0. 0. ]
[1. 0.17 0.34 0.56 0. ]
[1. 0.1 0. 0.02 0. ]
[0.04 0. 1. 0.06 0. ]
[0.03 0. 0. 1. 0. ]
[1. 0.93 0. 0.45 0. ]
[0.54 0.49 1. 0.4 0. ]
[1. 0. 0.36 0. 0. ]
[0.95 1. 0. 0.36 0. ]
[0.78 0.51 1. 0. 0. ]
[0.21 0.15 1. 0.25 0. ]
[0.96 0.94 1. 0.79 0. ]
[1. 0.62 0.17 0.7 0. ]
[0.08 0.02 0.57 1. 0. ]]
Note the extra column of zeros at index 4. There are 4 AFSCs (0, 1, 2, 3) but we make an extra for the unmatched AFSC (always at the end!).
When we generate random data, and if we have at least 4 AFSCs, I make sure I generate at least one AFSC from each of the three "accessions groups": Rated, USSF, NRL. You can track which AFSCs are in which group here:
# "Accessions Groups", and their associated AFSCs, represented in this instance:
instance.parameters['afscs_acc_grp']
💻 Console Output
{'Rated': array(['R2', 'R4'], dtype=object),
'USSF': array(['R1'], dtype=object),
'NRL': array(['R3'], dtype=object)}
# Indices of AFSCs in each accessions group
for grp in instance.parameters['afscs_acc_grp']:
param = "J^" + grp
print(param, instance.parameters[param])
💻 Console Output
J^Rated [1 3]
J^USSF [0]
J^NRL [2]
The next 7 columns all refer to the quantities of cadets assigned to the AFSCs. The USAFA and ROTC "targets" are taken from the Production Guidance Letter (PGL) produced by A1PT. These outline how many new lieutenants need to be produced from both sources of commissioning.
# Number of USAFA cadets needed for each AFSC
print('USAFA:', instance.parameters['usafa_quota'])
# Number of ROTC cadets needed for each AFSC
print('ROTC', instance.parameters['rotc_quota'])
💻 Console Output
USAFA: [1. 1. 0. 0.]
ROTC [7. 4. 2. 2.]
These numbers are largely ignored since the real goal is meeting the combination of the two targets. If we were strict on meeting these quotas for both sources of commissioning it would be very challenging and result in a worse outcome for everyone. Therefore, the main PGL target we shoot for is aptly named "PGL Target".
# Real quota of cadets needed for each AFSC
instance.parameters['pgl']
💻 Console Output
array([8., 5., 2., 2.])
The "Estimated" and "Desired" numbers of cadets are both used purely in the Value-Focused Thinking (VFT) model. The VFT model, as it stands, is non-linear and non-convex since there is a variable divided by another variable in the objective function. For example, the "average merit" calculation for a particular AFSC \(j\) is:
Because it is non-linear, I created an "approximate" model where I approximate the number of cadets using some estimated number, hence, the "Estimated" parameter! The "Desired" parameter is fed into the quota value function which I will discuss later on.
# Estimated number of cadets for each AFSC (Used in objective function as denominator for certain objectives)
print("Estimated:", instance.parameters['quota_e'])
# Desired number of cadets for each AFSC (same as above because it's fake data)
print("Desired:", instance.parameters['quota_d'])
💻 Console Output
Estimated: [8. 8. 3. 2.]
Desired: [8. 8. 3. 2.]
Since the VFT model is no longer used by AFPC to match the cadets, there isn't much use in tuning these values, so they simply remain equal to the PGL target.
Because the PGL target only provides one data point, I still need to have a range on the number of cadets that can be assigned. This is where the minimum and maximum quantities are used (lower and upper bounds on the number of cadets to be assigned).
# Minimum number of cadets that can be assigned to each AFSC
print('Minimum:', instance.parameters['quota_min'])
# Maximum number of cadets that can be assigned to each AFSC
print('Maximum:', instance.parameters['quota_max'])
💻 Console Output
Minimum: [8. 5. 2. 2.]
Maximum: [9. 9. 3. 3.]
The "Deg Tier" columns contain the data on the target proportions of degrees from each tier requested for the AFSCs. This information is gathered into the value parameters that will be discussed later on.
instance.parameters['Deg Tiers']
💻 Console Output
array([['M > 0.27', 'P < 0.73', '', ''],
['P = 1', 'I = 0', '', ''],
['M = 1', 'I = 0', '', ''],
['P = 1', 'I = 0', '', '']], dtype='<U8')
3. Parameter "Additions"¶
From this initial set of data, we can derive more parameters and sets to use in the various models.
# Numbers of Cadets, AFSCs, and AFSC preferences
for param in ['N', 'M', 'P']:
print(param + ':', instance.parameters[param])
💻 Console Output
N: 20
M: 4
P: 4
These additional sets, subsets, parameters, etc. are constructed as part of the
parameter_sets_additions() function in
the data.adjustments module. This function is executed often, since any slight data modification could tweak the
underlying sets and parameters that are ultimately used by the models and algorithms.
# Sets of cadets and AFSCs (indices)
for param in ['I', 'J']:
print(param, instance.parameters[param])
💻 Console Output
I [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
J [0 1 2 3]
My sets of cadets and AFSCs (\(\mathcal{I}\) and \(\mathcal{J}\)) are numpy arrays of indices since this allows for more flexibility than just using AFSC/cadet names since we can access other arrays using those indices through the power of numpy.
# Set of cadets that are eligible for AFSC at index 2 (R3)
print('cadet indices', instance.parameters['I^E'][2])
💻 Console Output
cadet indices [ 2 3 5 6 7 9 12 13 15 16 17 18 19]
# Set of AFSCs that the cadet at index 14 is eligible for
print('AFSC indices', instance.parameters['J^E'][14])
💻 Console Output
AFSC indices [0 1 3]
# Names of the AFSCs that the cadet at index 14 is eligible for
print("AFSC Names:", instance.parameters['afscs'][instance.parameters['J^E'][14]])
💻 Console Output
AFSC Names: ['R1' 'R2' 'R4']
# USAFA cadets
print("USAFA cadets", instance.parameters['usafa_cadets'])
# ROTC cadets
print("ROTC cadets", instance.parameters['rotc_cadets'])
💻 Console Output
USAFA cadets [ 1 6 10 14 15 16 17]
ROTC cadets [ 0 2 3 4 5 7 8 9 11 12 13 18 19]
I have a dictionary \(I^D\) which contains the cadets with certain demographics that are also eligible for the various AFSCs. Many of these sets and subets are also discussed in my thesis.
# The keys to the "I^D" dictionary are the objectives for the AFSCs that deal with demographics of the cadets
print(instance.parameters['I^D'].keys())
💻 Console Output
dict_keys(['USAFA Proportion', 'Mandatory', 'Desired', 'Permitted', 'Tier 1', 'Tier 2', 'Tier 3', 'Tier 4'])
The objectives above are a subset of the possible AFSC objectives \(\mathcal{K}\) and are used with the value parameters that I will discuss in a later section!
# Cadets with Tier 2 degrees that are eligible for the AFSC at index 3 (R4)
print("Cadets:", instance.parameters['I^D']['Tier 2'][3])
💻 Console Output
Cadets: [ 3 6 13 15]
# USAFA Cadets with Tier 2 degrees that are eligible for the AFSC at index 3 (R4)
usafa_cadets_with_tier_2_degrees_afsc_r4 = \
np.intersect1d(instance.parameters['I^D']['Tier 2'][3], instance.parameters['usafa_cadets'])
print("Intersection:", usafa_cadets_with_tier_2_degrees_afsc_r4)
💻 Console Output
Intersection: [ 6 15]
# The OM of those cadets
print('Merit', instance.parameters['merit'][usafa_cadets_with_tier_2_degrees_afsc_r4])
💻 Console Output
Merit [0.84872693 0.26121946]
4. Preferences¶
Cadet preferences, as well as AFSC preferences now, are provided as numpy arrays of shape (NxM) with an extra column for cadet preferences for the unmatched AFSC (like the utility matrix shown earlier). Let's discuss cadet preferences first. There are multiple csv files containing information on cadet and AFSC preferences.
Cadet Preferences¶
For cadets, there is the utility matrix I depicted earlier which is contained in
"Random_1 Cadets Utility.csv":
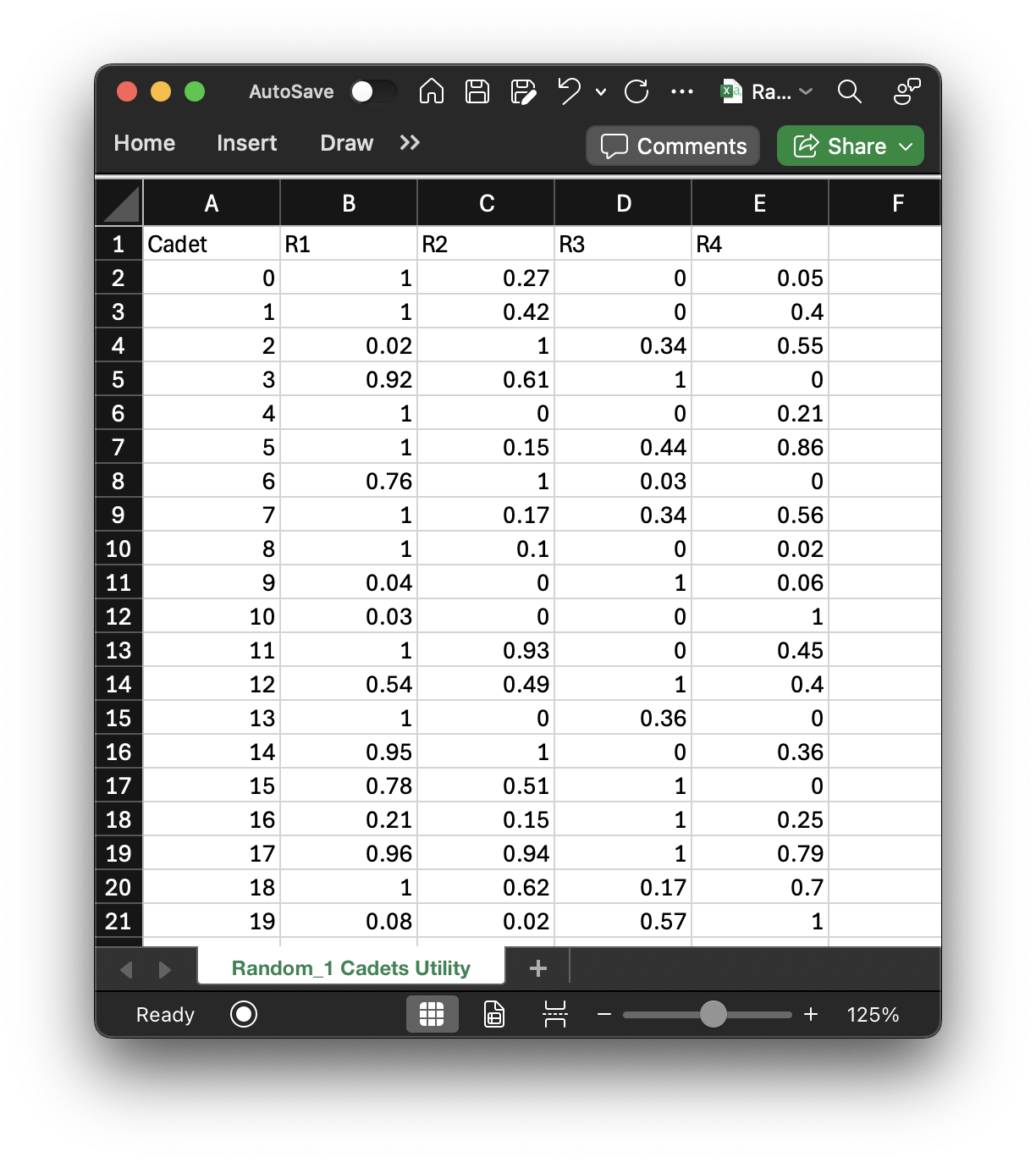
As you can see, the data is the same as was printed from "instance.parameters['utility']" earlier (near the start of the AFSCs section), with the exception of the extra column for the unmatched AFSC, "*". If I want to access Cadet 5's utility for the AFSC at index 2 (R3), I can do so like this:
instance.parameters['utility'][5, 2]
💻 Console Output
0.44
Remember, python index starts at 0! This "utility" matrix is meant to represent the cadet's reported utility for the AFSC they receive. Here's a little history on this real problem:
Up until FY24, cadets were allowed to express 6 preferences for NRL AFSCs and assign utility values to each. This was the extent of their input to the process, and the optimization model just used those utility values. Ties are allowed and are regularly provided by cadets by expressing multiple 100% utilities for their top however many choices. Often 0s were also expressed signaling the cadets lack of desire for a given AFSC (even within their top 6).
For the FY24 class, cadets rank ordered all 47 AFSCs (I know- yikes!) and were allowed to express utility values on
their top 10 choices (same rules as before). For FY25, FY26, and beyond, cadets must place a minimum of 10 preferences
(NRL/Rated/USSF combined) but may rank as many past 10 as they desire. They then also provide utility values on their
top 10 preferences, just as before. This essentially creates two separate matrices: c_pref_matrix and
utility. "Random_1 Cadets Preferences.csv" contains the preference matrix (c_pref_matrix):
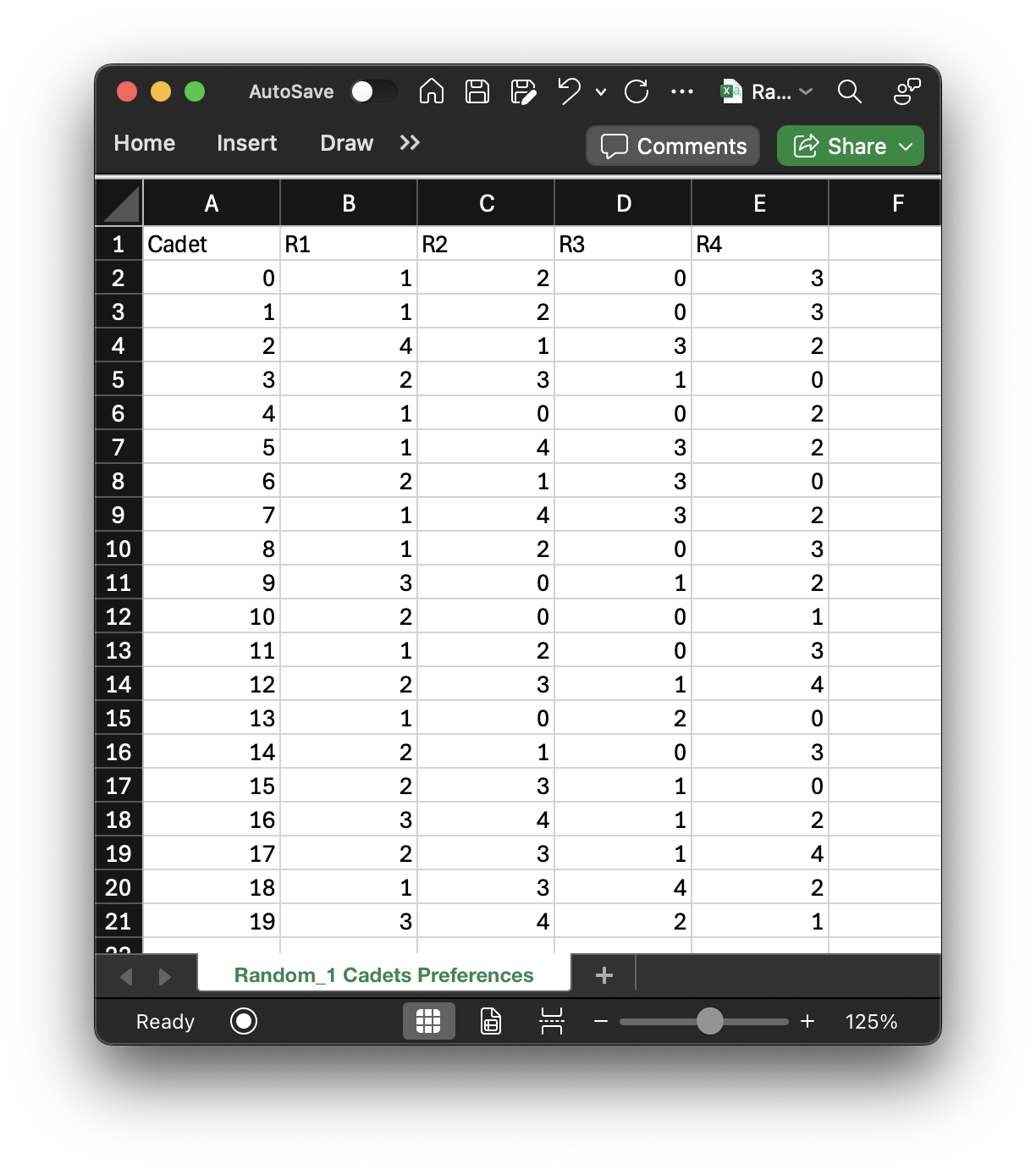
The "Cadets Utility" and "Cadets Preferences" files are both extracted into their numpy array counterparts,
utility and c_pref_matrix, respectively, within the
import_afsc_cadet_matrices_data()
function. In fact, the remainder of data elements discussed in Tutorial 3 are processed by this function since they
all follow the 2 dimensional cadet-AFSC row-column relationship.
instance.parameters['c_pref_matrix']
💻 Console Output
array([[1, 2, 0, 3],
[1, 2, 0, 3],
[4, 1, 3, 2],
[2, 3, 1, 0],
[1, 0, 0, 2],
[1, 4, 3, 2],
[2, 1, 3, 0],
[1, 4, 3, 2],
[1, 2, 0, 3],
[3, 0, 1, 2],
[2, 0, 0, 1],
[1, 2, 0, 3],
[2, 3, 1, 4],
[1, 0, 2, 0],
[2, 1, 0, 3],
[2, 3, 1, 0],
[3, 4, 1, 2],
[2, 3, 1, 4],
[1, 3, 4, 2],
[3, 4, 2, 1]])
NOTE: this matrix takes on the same format as before where the rows are the cadets and the columns are the AFSCs (NOT the "choice" of the cadets; the matrix cell values are the rank that the cadet put on that AFSC column). Cadet 2, for example, ranks AFSC "R2" first followed by "R4" then "R3" then "R1". The "0"s represent an AFSC that is not on a cadet's preference list. I will touch on the concept of "eligibility" later, but this effectively means that this cadet cannot be matched to this particular AFSC. Once we have the "c_pref_matrix", we can then convert it to an ordered list of AFSCs for each cadet. I have that piece as a dictionary where the keys are the cadets and the values are lists of AFSC indices in order of the cadet's ranking of them:
instance.parameters['cadet_preferences']
💻 Console Output
{0: array([0, 1, 3]),
1: array([0, 1, 3]),
2: array([1, 3, 2, 0]),
3: array([2, 0, 1]),
4: array([0, 3]),
5: array([0, 3, 2, 1]),
6: array([1, 0, 2]),
7: array([0, 3, 2, 1]),
8: array([0, 1, 3]),
9: array([2, 3, 0]),
10: array([3, 0]),
11: array([0, 1, 3]),
12: array([2, 0, 1, 3]),
13: array([0, 2]),
14: array([1, 0, 3]),
15: array([2, 0, 1]),
16: array([2, 3, 0, 1]),
17: array([2, 0, 1, 3]),
18: array([0, 3, 1, 2]),
19: array([3, 2, 0, 1])}
Cadet 0's preferences in order with AFSC names:
cadet_0_afsc_indices = instance.parameters['cadet_preferences'][0]
# Ordered list of AFSC names for cadet 0
instance.parameters['afscs'][cadet_0_afsc_indices]
💻 Console Output
array(['R1', 'R2', 'R4'], dtype=object)
We have the ordinal preferences that the cadets provide and we have the utility values they provide. These are two
different pieces of information that we must aggregate together to form one "final" cadet utility matrix. For this
random dataset, and for the FY24 class, we convert the ordinal rankings (1, 2, 3, 4, 5) to a continuous 1 -> 0 scale
(1, 0.8, 0.6, 0.4, 0.2). We then average these converted rankings and the provided utility values to get the final
cadet utility matrix, cadet_utility, which is located in "Random_1 Cadets Utility (Final).csv". This occurs in the
create_new_cadet_utility_matrix()
function. For FY25, FY26, and beyond, we utilize additional information on the cadet's bottom choices and on the
AFSCs they did not select in their preferences to construct the cadet_utility matrix. The math behind this operation is located in the
create_final_cadet_utility_matrix_from_new_formula()
function.
instance.parameters['cadet_utility']
💻 Console Output
array([[1. , 0.4683, 0. , 0.1917],
[1. , 0.5433, 0. , 0.3667],
[0.135 , 1. , 0.42 , 0.65 ],
[0.7933, 0.4717, 1. , 0. ],
[1. , 0. , 0. , 0.355 ],
[1. , 0.2 , 0.47 , 0.805 ],
[0.7133, 1. , 0.1817, 0. ],
[1. , 0.21 , 0.42 , 0.655 ],
[1. , 0.3833, 0. , 0.1767],
[0.1867, 0. , 1. , 0.3633],
[0.265 , 0. , 0. , 1. ],
[1. , 0.7983, 0. , 0.3917],
[0.645 , 0.495 , 1. , 0.325 ],
[1. , 0. , 0.43 , 0. ],
[0.8083, 1. , 0. , 0.3467],
[0.7233, 0.4217, 1. , 0. ],
[0.355 , 0.2 , 1. , 0.5 ],
[0.855 , 0.72 , 1. , 0.52 ],
[1. , 0.56 , 0.21 , 0.725 ],
[0.29 , 0.135 , 0.66 , 1. ]])
Just as a reminder, here is the initial utility matrix (note the extra column for AFSC "*"):
instance.parameters['utility']
💻 Console Output
array([[1. , 0.27, 0. , 0.05, 0. ],
[1. , 0.42, 0. , 0.4 , 0. ],
[0.02, 1. , 0.34, 0.55, 0. ],
[0.92, 0.61, 1. , 0. , 0. ],
[1. , 0. , 0. , 0.21, 0. ],
[1. , 0.15, 0.44, 0.86, 0. ],
[0.76, 1. , 0.03, 0. , 0. ],
[1. , 0.17, 0.34, 0.56, 0. ],
[1. , 0.1 , 0. , 0.02, 0. ],
[0.04, 0. , 1. , 0.06, 0. ],
[0.03, 0. , 0. , 1. , 0. ],
[1. , 0.93, 0. , 0.45, 0. ],
[0.54, 0.49, 1. , 0.4 , 0. ],
[1. , 0. , 0.36, 0. , 0. ],
[0.95, 1. , 0. , 0.36, 0. ],
[0.78, 0.51, 1. , 0. , 0. ],
[0.21, 0.15, 1. , 0.25, 0. ],
[0.96, 0.94, 1. , 0.79, 0. ],
[1. , 0.62, 0.17, 0.7 , 0. ],
[0.08, 0.02, 0.57, 1. , 0. ]])
One last data element for the cadets that is used on the real data, but not the random data, is the "Cadets Selected"
csv which is loaded in as c_selected_matrix. This is a binary matrix indicating if cadet \(i\) selected AFSC \(j\) as a
preference on the survey. This was added for FY25, but is not currently generated as part of the random data generator.
AFSC Preferences¶
As of FY24, AFSCs have preferences on cadets too now! For the Non-Rated Line AFSCs, we actually met with all the Career
Field Managers (CFMs) to discuss what was important to them in their officers.
They provided their input and "1-N" lists were created for each of their respective AFSCs.
For Rated, each Source of Commissioning (SOC) acted as the CFM and their specific order of merit (OM) lists were used as
the 1-Ns. I will touch on the Rated OM data momentarily. The Space Force did a similar thing for their AFSCs.
This is all captured in the "Random_1 AFSCs Preferences.csv" file in a very similar manner as the "Cadets Preferences"
version. Now, each column contains an AFSC's ranking for each cadet in a_pref_matrix:
instance.parameters['a_pref_matrix']
💻 Console Output
array([[ 6, 16, 0, 16],
[ 9, 13, 0, 12],
[20, 6, 13, 10],
[17, 12, 11, 0],
[10, 0, 0, 11],
[13, 14, 12, 9],
[ 7, 2, 9, 0],
[ 1, 8, 5, 4],
[12, 15, 0, 15],
[19, 0, 4, 13],
[ 4, 0, 0, 1],
[16, 9, 0, 14],
[11, 5, 2, 6],
[ 3, 0, 10, 0],
[ 2, 1, 0, 8],
[15, 10, 7, 0],
[14, 7, 1, 7],
[ 8, 4, 3, 5],
[ 5, 3, 8, 2],
[18, 11, 6, 3]])
Again, 0s represent cadets that are not on the AFSC's list.
In the exact same manner I mentioned previously with converting cadet ordinal rankings (1, 2, 3, 4, 5) to a continuous
scale (1, 0.8, 0.6, 0.4, 0.2), we do that with AFSCs to get the afsc_utility matrix located in "Random_1 AFSCs Utility.csv":
instance.parameters['afsc_utility']
💻 Console Output
array([[0.75 , 0.0625, 0. , 0.0625],
[0.6 , 0.25 , 0. , 0.3125],
[0.05 , 0.6875, 0.0769, 0.4375],
[0.2 , 0.3125, 0.2308, 0. ],
[0.55 , 0. , 0. , 0.375 ],
[0.4 , 0.1875, 0.1538, 0.5 ],
[0.7 , 0.9375, 0.3846, 0. ],
[1. , 0.5625, 0.6923, 0.8125],
[0.45 , 0.125 , 0. , 0.125 ],
[0.1 , 0. , 0.7692, 0.25 ],
[0.85 , 0. , 0. , 1. ],
[0.25 , 0.5 , 0. , 0.1875],
[0.5 , 0.75 , 0.9231, 0.6875],
[0.9 , 0. , 0.3077, 0. ],
[0.95 , 1. , 0. , 0.5625],
[0.3 , 0.4375, 0.5385, 0. ],
[0.35 , 0.625 , 1. , 0.625 ],
[0.65 , 0.8125, 0.8462, 0.75 ],
[0.8 , 0.875 , 0.4615, 0.9375],
[0.15 , 0.375 , 0.6154, 0.875 ]])
Also in the same manner as cadets, we have a separate dictionary of ordered cadets for each AFSC:
instance.parameters['afsc_preferences']
💻 Console Output
{0: array([ 7, 14, 13, 10, 18, 0, 6, 17, 1, 4, 12, 8, 5, 16, 15, 11, 3, 19, 9, 2]),
1: array([14, 6, 18, 17, 12, 2, 16, 7, 11, 15, 19, 3, 1, 5, 8, 0]),
2: array([16, 12, 17, 9, 7, 19, 15, 18, 6, 13, 3, 5, 2]),
3: array([10, 18, 19, 7, 17, 12, 16, 14, 5, 2, 4, 1, 9, 11, 8, 0])}
In the above, the AFSC at index 0 (R1) has cadet 7 ranked #1 (first) and cadet 0 ranked #6.
Just to confirm that these lists are the "sorted indices" of "a_pref_matrix", you can look at both the utilities and rankings of the cadets using "afsc_preferences" as the indices to sort on. We'll use AFSC 'R2' as an example:
j = 1 # Index of "R2"
sorted_indices = instance.parameters['afsc_preferences'][j]
print('Ordered cadets:', sorted_indices)
print('Rankings on these cadets:', instance.parameters['a_pref_matrix'][sorted_indices, j])
print('Utilities on these cadets:', instance.parameters['afsc_utility'][sorted_indices, j])
💻 Console Output
Ordered cadets: [14 6 18 17 12 2 16 7 11 15 19 3 1 5 8 0]
Rankings on these cadets: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16]
Utilities on these cadets: [1. 0.9375 0.875 0.8125 0.75 0.6875 0.625 0.5625 0.5 0.4375 0.375 0.3125 0.25 0.1875 0.125 0.0625]
There you have it as far as cadet and AFSC preferences go! I will soon discuss why eligibility is important as it directly relates to who is or is not on each of the lists. First, let's discuss the rated OM situation.
Rated OM¶
Currently, each SOC provides their own rated OM lists that we need to combine. The lists for ROTC and USAFA are located
in "Random_1 ROTC Rated OM.csv" and "Random_1 USAFA Rated OM.csv", respectively. They are loaded into
rr_om_matrix and ur_om_matrix, respectively, as well:
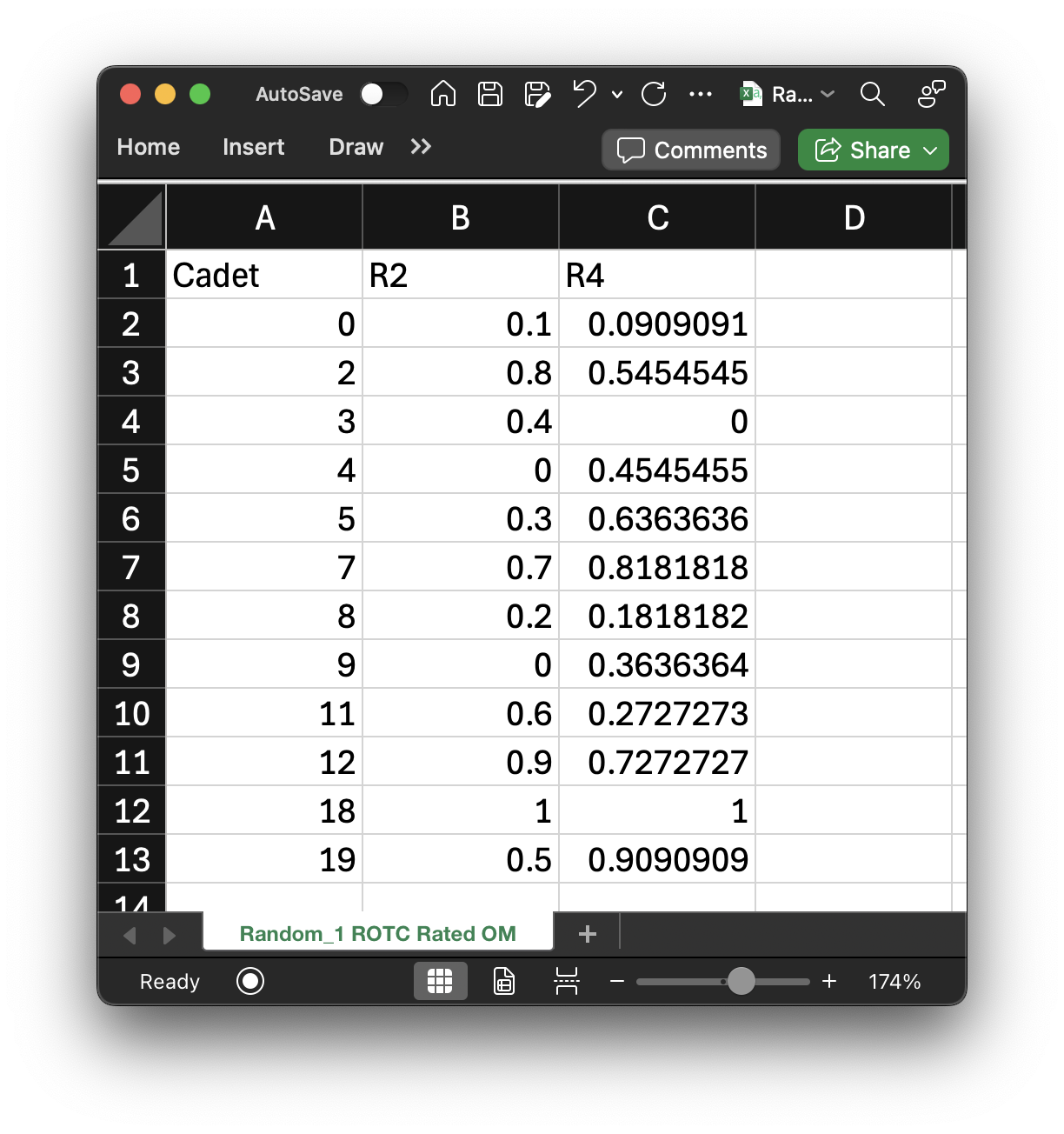
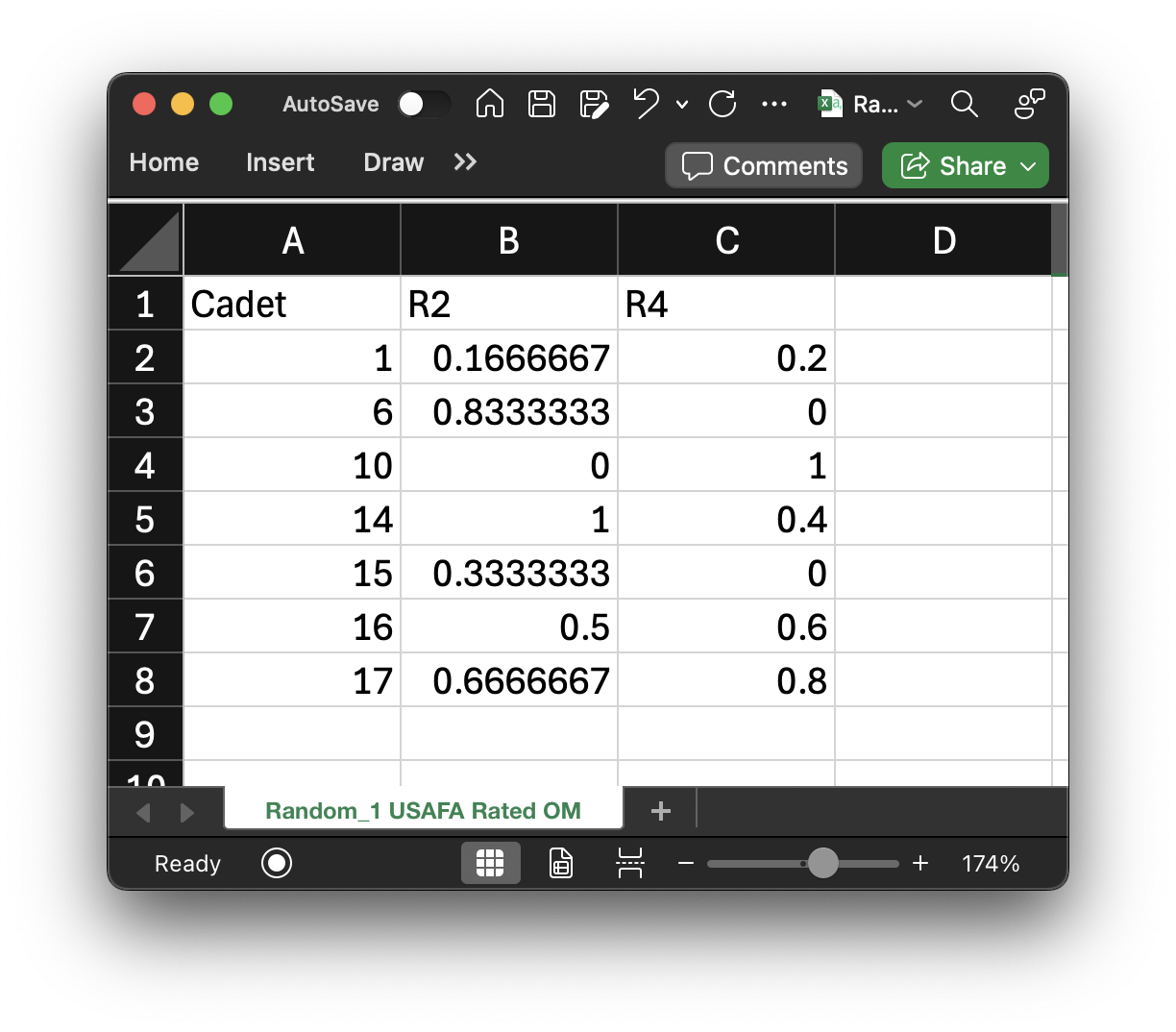
One of the reasons I like using cadet indices as identifiers (rather than some other ID or name) is for this example right here. I can extract the indices of the rated cadets from both SOCs directly from these matrices:
instance.parameters['Rated Cadets']
💻 Console Output
{'usafa': array([ 1, 6, 10, 14, 15, 16, 17]),
'rotc': array([ 0, 2, 3, 4, 5, 7, 8, 9, 11, 12, 18, 19])}
Once I have that, I can look at whatever other features I want to see from these cadets. For example:
# General Order of Merit
indices = instance.parameters['Rated Cadets']['usafa']
print('GOM:', instance.parameters['merit'][indices])
# Preference of the rated USAFA cadets for the rated AFSC 'R4'
print('Cadet preference on R4:', instance.parameters['c_pref_matrix'][indices, 3])
💻 Console Output
GOM: [0.172255 0.84872693 0.95458219 0.79412205 0.26121946 0.90382693 0.57759659]
Cadet preference on R4: [3 0 1 3 0 2 4]
Since both of these lists for R4 are relative to each SOC, we can combine them like we do with general OM.
We convert to "percentiles" relative to the SOCs and then zipper them together. I have a method that does this:
construct_rated_preferences_from_om_by_soc().
It takes these two matrices and then zippers them together where the final product is an updated a_pref_matrix and
afsc_preferences. Let's demonstrate the "zippering":
j = 3 # R4
# Alternating USAFA/ROTC cadets based on proportions of both SOCs in R4's list
sorted_indices = instance.parameters['afsc_preferences'][j]
print('Binary USAFA array:', instance.parameters['usafa'][sorted_indices])
print('Ordered Cadet List:', sorted_indices)
💻 Console Output
Binary USAFA array: [1 0 0 0 1 0 1 1 0 0 0 1 0 0 0 0]
Ordered Cadet List: [10 18 19 7 17 12 16 14 5 2 4 1 9 11 8 0]
5. Eligibility/Qualifications¶
One thing I've alluded to in several areas before is the concept of eligibility. Certain cadet/AFSC pairings cannot happen. Rated eligibility is determined by medical qualifications and volunteerism. Space Force eligibility is determined by degree qualifications and volunteerism (for FY24, but now it is SOC-based as well). NRL AFSC eligibility is a combination of degree qualifications and the new CFM rankings via the AFSC preferences. The intent for them was to open the door to more people potentially being eligible for certain career fields based on factors beyond academic degrees.
The degree qual matrix outlines the tier of degree that each cadet has, but it also signals which cadets are
eligible or not for each of the AFSCs. For rated, everyone is a "P" unless you're ineligible
(see below for "R2" & "R4"):
# Degree Qualification matrix (AFOCD)
print(instance.parameters['qual'])
💻 Console Output
[['M1' 'P1' 'I2' 'P1']
['M1' 'P1' 'I2' 'P1']
['P2' 'P1' 'M1' 'P1']
['P2' 'P1' 'M1' 'I2']
['M1' 'I2' 'I2' 'P1']
['P2' 'P1' 'M1' 'P1']
['P2' 'P1' 'M1' 'I2']
['M1' 'P1' 'M1' 'P1']
['M1' 'P1' 'I2' 'P1']
['P2' 'I2' 'M1' 'P1']
['M1' 'I2' 'I2' 'P1']
['P2' 'P1' 'I2' 'P1']
['P2' 'P1' 'M1' 'P1']
['M1' 'I2' 'M1' 'I2']
['M1' 'P1' 'I2' 'P1']
['P2' 'P1' 'M1' 'I2']
['P2' 'P1' 'M1' 'P1']
['P2' 'P1' 'M1' 'P1']
['P2' 'P1' 'M1' 'P1']
['P2' 'P1' 'M1' 'P1']]
# Embedded eligibility matrix
print(instance.parameters['eligible'])
💻 Console Output
[[1 1 0 1]
[1 1 0 1]
[1 1 1 1]
[1 1 1 0]
[1 0 0 1]
[1 1 1 1]
[1 1 1 0]
[1 1 1 1]
[1 1 0 1]
[1 0 1 1]
[1 0 0 1]
[1 1 0 1]
[1 1 1 1]
[1 0 1 0]
[1 1 0 1]
[1 1 1 0]
[1 1 1 1]
[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
In the age of wanting to try matching algorithms, preferences on both sides (cadets and AFSCs) must agree. This means that if you're on one AFSC's preference list, that AFSC must be on your preference list too. Essentially, this creates three separate eligibility sources (cadet preferences, afsc preferences, and the qual matrix). All three of these need to match up. This is why I have one method of CadetCareerProblem that "ensures" this is true: instance.remove_ineligible_choices(). This is a fairly aggressive approach since all it does is check if you're ineligible according to one source, and if you are, it removes you from all other sources to force ineligibility. If you're doing this for real data, make sure you know what you're doing! Here's the code I have in the instance.fix_generated_data() method when I remove these choices to show what you need to do afterwards to get the data looking right:
# Removes ineligible cadets from all 3 matrices: degree qualifications, cadet preferences, AFSC preferences
instance.remove_ineligible_choices()
# Take the preferences dictionaries and update the matrices from them (using cadet/AFSC indices)
instance.update_preference_matrices() # 1, 2, 4, 6, 7 -> 1, 2, 3, 4, 5 (preference lists need to omit gaps)
# Convert AFSC preferences to percentiles (0 to 1)
instance.convert_afsc_preferences_to_percentiles() # 1, 2, 3, 4, 5 -> 1, 0.8, 0.6, 0.4, 0.2
# The "cadet columns" are located in Cadets.csv and contain the utilities/preferences in order of preference
instance.update_cadet_columns_from_matrices() # We haven't touched "c_preferences" and "c_utilities" until now
💻 Console Output
Removing ineligible cadets based on any of the three eligibility sources (c_pref_matrix, a_pref_matrix, qual)...
0 total adjustments.
Updating cadet preference matrices from the preference dictionaries. ie. 1, 2, 4, 6, 7 -> 1, 2, 3, 4, 5 (preference lists need to omit gaps)
Converting AFSC preferences (a_pref_matrix) into percentiles (afsc_utility on AFSCs Utility.csv)...
Updating cadet columns (Cadets.csv...c_utilities, c_preferences) from the preference matrix (c_pref_matrix)...
No changes are made because I've already done this earlier!
6. Note on Parameters¶
To drive home the idea that my "parameters" dictionary is an attribute of the problem instance I've been writing
"instance.parameters" up until this point. In most of my functions within afccp, however, I convert
"instance.parameters" to "p" for sake of typing less which I highly encourage you to do when writing your own functions.
# Shorthand example
p = instance.parameters
p['afscs']
💻 Console Output
array(['R1', 'R2', 'R3', 'R4', '*'], dtype=object)
There are plenty of other parameters attached to this dictionary that you can explore.
Parameters Details¶
-
Qual Type(str):The qualification tiering rule set in use (e.g., "Tiers", "Legacy", "Binary").
-
afscs(np.ndarray[M+1]):Array of AFSCs (Air Force Specialty Codes) used in the model. Extra AFSC is unmatched "*".
-
acc_grp(np.ndarray[M]):Mapping of AFSCs to their accession groups.
-
usafa_quota,rotc_quota(np.ndarray[M]):Number of available positions for USAFA and ROTC cadets, respectively.
-
pgl(np.ndarray[M]):
Production Guidance Letter (PGL) targets for each AFSC. -
quota_e,quota_d,quota_min,quota_max(np.ndarray[M]):
AFSC-specific quota constraints (estimated, desired, min, max values). -
M(int):
Total number of AFSCs (Does NOT include unmatched AFSC "*"). -
Deg Tiers(np.ndarray[M, 4]):
Array representing degree tier categories and constraints for each AFSC and tier (tiers 1 -> 4) -
cadets(np.ndarray[N]):
Array of cadet indices -
assigned(np.ndarray[N]):
Sparse array containing data for cadets that are fixed to certain AFSCs. -
usafa,rotc(np.ndarray[N]):
Binary vectors indicating if cadets are from the respective SOC or not. -
soc(np.ndarray[N]):
Source of Commissioning (str) for each cadet (e.g., USAFA, ROTC, OTS). -
merit,merit_all(np.ndarray[N]):
Cadet order of merit percentiles. -
N(int):
Number of cadets. -
eligible,ineligible(np.ndarray[N, M]):
Boolean arrays indicating cadet eligibility (& ineligibility) for AFSCs. -
tier 1,tier 2,tier 3,tier 4(np.ndarray[N, M]):
Tiered qualification matrices (binary) by AFSC. -
mandatory,desired,permitted,exception(np.ndarray[N, M]):
AFSC qualification matrices categorized by tier level (e.g., "M", "D", "P", "E"). -
t_count(np.ndarray[M]):
Total number of tiers contained in each AFSC -
t_proportion(np.ndarray[M, 4]):
Proportion of cadets desired by each tier. -
t_leq,t_geq,t_eq(np.ndarray[M, 4]):
Boolean or integer matrices indicating if the tier is a≤,≥, or=constraint. -
t_mandatory,t_desired,t_permitted(np.ndarray):
Boolean or integer matrices indicating if the tier is a "M", "D", or "P" constraint. -
qual(np.ndarray[N, M]):
Final qualification tier matrix by cadet and AFSC (e.g., “M1”, “D2”). -
P(int):Max number of cadet preferences they were allowed to provide. This is not a very useful parameter to be honest as this is a legacy model idea.
-
num_util(int):
Max number of utilities the cadets were allowed to provide. This is 10 in the real problem. -
c_preferences(np.ndarray[N, P]):Cadet preferences in easy-to-read column form. Each row corresponds to a given cadet's ordered preferences of the AFSCs (and it contains the AFSC names, not indices). This is what is found in the "Cadets.csv".
-
c_utilities(np.ndarray[N, num_util]):Cadet utilities in easy-to-read column form. Each row corresponds to a given cadet's ordered utilities of the AFSCs. This is what is found in the "Cadets.csv".
-
SOCs(list[str]):
Unique SOC categories used in the problem, i.e.,['usafa', 'rotc', 'ots']. Or, historically,['usafa', 'rotc']. -
utility,cadet_utility(np.ndarray[N, M]):Cadet utility matrices.
utilityis the directly cadet-provided matrix andcadet_utilityis the calculated matrix used in the optimization models. -
c_pref_matrix,a_pref_matrix(np.ndarray[N, M]):
Cadet and AFSC preference matrices. Each row is the preference on the specific cadet-AFSC pair, either from the cadet's perspective (c_pref_matrix) or from the AFSC's perspective (a_pref_matrix). -
afsc_utility(np.ndarray[N, M]):
AFSC utility matrix. This is the preference matrix converted to linearized percentiles. -
usafa_cadets,rotc_cadets(np.ndarray):
Arrays of cadet indices filtered by commissioning source. If there are 4 cadets total[0, 1, 2, 3]and cadet '1' is from USAFA and the other three are ROTC, thenusafa_cadetswould be[1]androtc_cadetswould be[0, 2, 3]. -
rr_interest_matrix(np.ndarray):
Legacy ROTC rated "interest" matrix. They used to collect preferences on the Form 53 from ROTC cadets for rated AFSCs by asking them if they had "high", "medium", or "low" interest in each of the four AFSCs. This was a suboptimal process for a multitude of reasons, and I used this to show them the benefit of switching to the "One Market" idea. This variable is no longer in use. -
rr_om_matrix,ur_om_matrix(np.ndarray):
Rated order of merit (OM) matrices for both ROTC and USAFA. This data contains all the rankings for each rated AFSC for the rated cadets (cadets qualified for at least one rated AFSC). This is the data in the "Rated OM.csv" files. -
rr_om_cadets,ur_om_cadets(np.ndarray):
Cadet indices of ROTC and USAFA rated eligible cadets. These are the cadets that correspond to the OM matrices. -
I(np.ndarray[N]):
Array/set of all cadets[0, 1, ..., N - 1] -
J(np.ndarray[M]):
Array/set of all AFSCs[0, 1, ..., M - 1] -
J^E,I^E,I^Choice,I^D,I^P,I^USAFA,I^ROTC(dict[int, np.ndarray]):
Sets/subsets of cadets or AFSCs based on eligibility, choice, demographics, or commissioning source. -
num_eligible(np.ndarray[M]):
Number of cadets eligible for each AFSC -
Choice Count(dict[int, np.ndarray]):
Number of cadets who have each AFSC as their first (0) choice, second (1) choice, etc. Keys are the choice, values are arrays of how many people have each AFSC at that choice. -
usafa_proportion(float):
Proportion of USAFA cadets relative to all other cadets (ROTC, maybe OTS). -
Deg Tier Values(dict[str, int]):
Numerical mapping of tier labels to ordinal values (e.g., “M1”: 1). -
sum_merit(float):
Aggregate merit score used in optimization or normalization. -
usafa_eligible_count,rotc_eligible_count(int):
Count of eligible cadets by commissioning source. -
J^Fixed,J^Reserved,J^Rated,J^USSF,J^NRL,J^USAF,J^P(np.ndarray):
Specialized AFSC subsets (fixed, reserved, rated, USSF, non-rated, USAF, priority). -
Rated Cadets,Rated Cadet Index Dict(np.ndarray,dict):
List and mapping of rated cadets for tracking assignment requirements. -
Rated Choices,Num Rated Choices(np.ndarray,int):
Matrix and count of rated AFSC preferences submitted by cadets. -
w^G(float):
Overall weight onGUOmodel relative to CASTLE (0 to 1). -
N^Match(int):
Total number of cadets to match in the optimization model.
📌 Summary¶
This tutorial demonstrates how to initialize and prepare a full CadetCareerProblem instance using raw input data.
We walk through each major import function, illustrating how to load cadets, AFSCs, quotas, preferences, and utility
matrices from CSV files and transform them into structured parameter dictionaries.
Key steps include:
- Loading cadet and AFSC data within the
import_cadets_data()andimport_afscs_data()as part of theCadetCareerProbleminitialization. - Importing compatibility and preference matrices between cadets and AFSCs via
import_afsc_cadet_matrices_data(). - Generating cadet utility matrices, using tier, merit, and preference information to construct a personalized utility score for each cadet-AFSC pair.
- Finalizing model inputs for downstream evaluation or optimization by integrating all components into a unified parameter dictionary.
You’re now ready to explore how the value_parameters work in Tutorial 4!