Tutorial 2: Data Overview¶
In this second tutorial, we'll explain the contents of the data module within afccp, as well as how the data itself
is structured in the CadetCareerProblem object.
1. Data Module¶
A CadetCareerProblem instance comes with a lot of data, and so the largest section of this tutorial is here to
talk about that data. I'll outline where the data is coming from (the various csvs), how the data is captured within
the CadetCareerProblem class, and where the code is that manages all of it.
afccp.data¶
The "data" module of afccp contains the scripts and functions that all have something to do with processing the many sets and parameters of the problem. At a high level the modules are set up like this:
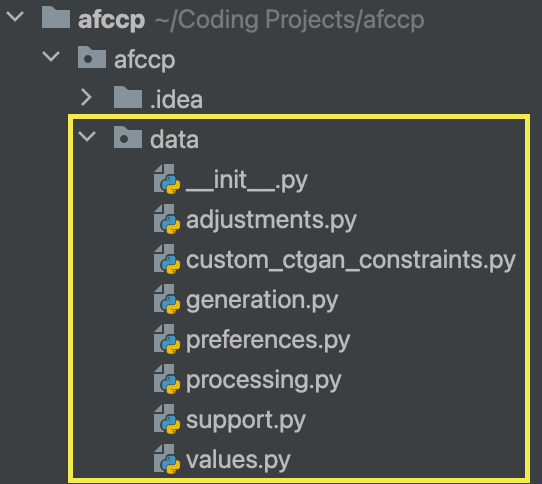
The "adjustments.py" script holds the functions that manipulate the parameters. There is also a function that sanity checks many sets and subsets of parameters here which is extremely important in avoiding preventable errors. For generating simulated data, "generation.py" contains those functions, and "custom_ctgan_constraints.py" contains some constraints for the CTGAN model used to generate realistic cadet data. Because I ended up making quite a few functions that deal with cadet and AFSC preferences, I took those and put them into "preferences.py". For importing and exporting data, as well as handling some file information, we have "processing.py". There are a few functions designated to support CadetCareerProblem and its hyperparameters and whatnot, so I put those into "support.py". Lastly, the value parameters, which I will discuss later, are all mostly handled by "values.py".
Hyperparameters: mdl_p¶
One thing I do across all my .py scripts is import each afccp module directly so that you can see which modules are
dependent on each other. All the core scripts get imported directly into "main" since this serves as the hub for all
the functionality of afccp. In other scripts, the modules imported are only the ones that are required.
Another thing I do for context is include the entire module "path" in front of each function when I call it so that
you can see where the function is written. For example, if I wanted to call the function that defines all afccp model
hyperparameters (mdl_p), I can do so like this:
# Import the "data.support" module (this would be at the top of the script)
import afccp.data.support
# Call the specific function from that script (this example returns a dictionary of default "hyper-parameters")
mdl_p = afccp.data.support.initialize_instance_functional_parameters(N=20) # Requires the number of cadets
# There is a lot of information in here used across afccp
print(mdl_p['figsize']) # This is the default figure size for my matplotlib plots!
The output, the default figure size of the matplotlib charts:
(19, 10)
🎲 Generating Data¶
CadetCareerProblem allows for "fake" class years using simulated data generated through various means. You may or may not have real class year data, but we can generate data to play around with here:
# Create a randomly generated problem instance with 20 cadets and 4 AFSCs
instance = CadetCareerProblem('Random', N=20, M=4, P=4)
💻 Console Output
Generating 'Random_1' instance...
Instance 'Random_1' initialized.
That one line above initializes a new instance of the cadet–AFSC matching problem (CadetCareerProblem).
N is the number of cadets, M is the number of AFSCs, and P is the number of preferences the cadets are allowed to express.
Originally, cadets could only express six preferences, but today they're able to provide complete preference lists.
I recommend always setting P = M for full preference rankings.
💡 What is data_name?
The first parameter in CadetCareerProblem('Random', N=20, M=4, P=4) is referred to as the data name.
When generating data, you can simply pass "Random" and the system will automatically create the next instance
(e.g., "Random_1") based on what already exists in your instances folder.
Since we haven’t generated or exported any data yet, this will create a new in-memory instance called "Random_1".
There will be no folder named Random_1 yet — we delay that until you explicitly call instance.export_data()
to avoid cluttering your working directory.
The next code block prepares the generated data to be exported as CSVs so we can reference them in other examples.
This block is only needed for generated data and is included here to give you a clean dataset to import and follow along with.
You don’t need to worry about this yet — just know that once it's exported, you can reload the same instance later.
# Fix "Random" data (only meant for generated data!!)
instance.fix_generated_data()
💻 Console Output
2 Making 4 cadets ineligible for 'R3' by altering their qualification to 'I2'.
3 Making 4 cadets ineligible for 'R4' by altering their qualification to 'I2'.
Removing ineligible cadets based on any of the three eligibility sources (c_pref_matrix, a_pref_matrix, qual)...
Edit 1: Cadet 0 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (0, 1) set to 0.
Edit 2: Cadet 4 not eligible for R4 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (4, 3) set to 0.
Edit 3: Cadet 5 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (5, 1) set to 0.
Edit 4: Cadet 5 not eligible for R3 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (5, 2) set to 0.
Edit 5: Cadet 6 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (6, 1) set to 0.
Edit 6: Cadet 7 not eligible for R4 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (7, 3) set to 0.
Edit 7: Cadet 8 not eligible for R4 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (8, 3) set to 0.
Edit 8: Cadet 9 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (9, 1) set to 0.
Edit 9: Cadet 10 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (10, 1) set to 0.
Edit 10: Cadet 12 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (12, 1) set to 0.
Edit 11: Cadet 12 not eligible for R4 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (12, 3) set to 0.
Edit 12: Cadet 14 not eligible for R3 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (14, 2) set to 0.
Edit 13: Cadet 15 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (15, 1) set to 0.
Edit 14: Cadet 15 not eligible for R3 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (15, 2) set to 0.
Edit 15: Cadet 18 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (18, 1) set to 0.
Edit 16: Cadet 18 not eligible for R3 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (18, 2) set to 0.
Edit 17: Cadet 19 not eligible for R2 based on degree qualification matrix but the AFSC was in the cadet preference list. c_pref_matrix position (19, 1) set to 0.
17 total adjustments.
Updating cadet preference matrices from the preference dictionaries. ie. 1, 2, 4, 6, 7 -> 1, 2, 3, 4, 5 (preference lists need to omit gaps)
Updating cadet first choice utility value to 100%...
Fixed 4 first choice cadet utility values to 100%.
Cadets: [6, 9, 14, 18]
Converting AFSC preferences (a_pref_matrix) into percentiles (afsc_utility on AFSCs Utility.csv)...
Updating cadet columns (Cadets.csv...c_utilities, c_preferences) from the preference matrix (c_pref_matrix)...
Updating cadet utility matrices ('utility' and 'cadet_utility') from the 'c_utilities' matrix
Modifying rated eligibiity lists/matrices by SOC...
(Removing cadets that are on the lists but not eligible for any rated AFSC)
Sanity checking the instance parameters...
Done, 0 issues found.
There are certainly a lot of things that happen when we "fix" the generated data. I will describe these steps in more detail later, but for more information on what is happening please refer to the fix_generated_data() method. Now we can export the data!
# Export everything
instance.export_data()
💻 Console Output
Exporting datasets ['Cadets', 'AFSCs', 'Preferences', 'Goal Programming', 'Value Parameters', 'Solutions', 'Additional', 'Base Solutions', 'Course Solutions']
Instance Folder Structure¶
Now that we've exported the data (after manipulating it a little), you should have a "Random_1" sub-folder within your "instances" folder:
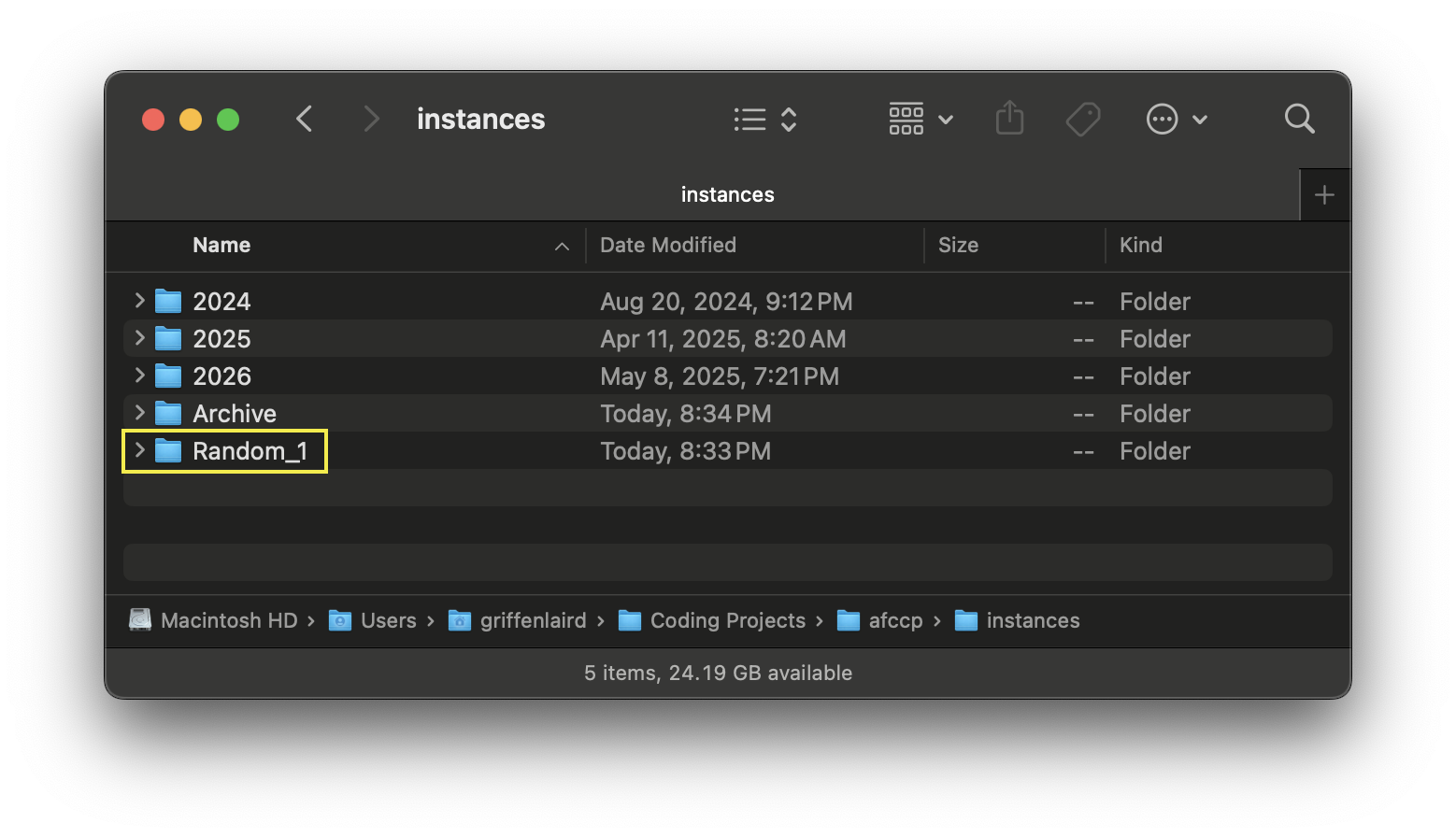
You have data now located within the "Random_1" sub-folder. There are 5 instance sub-folders that get created:
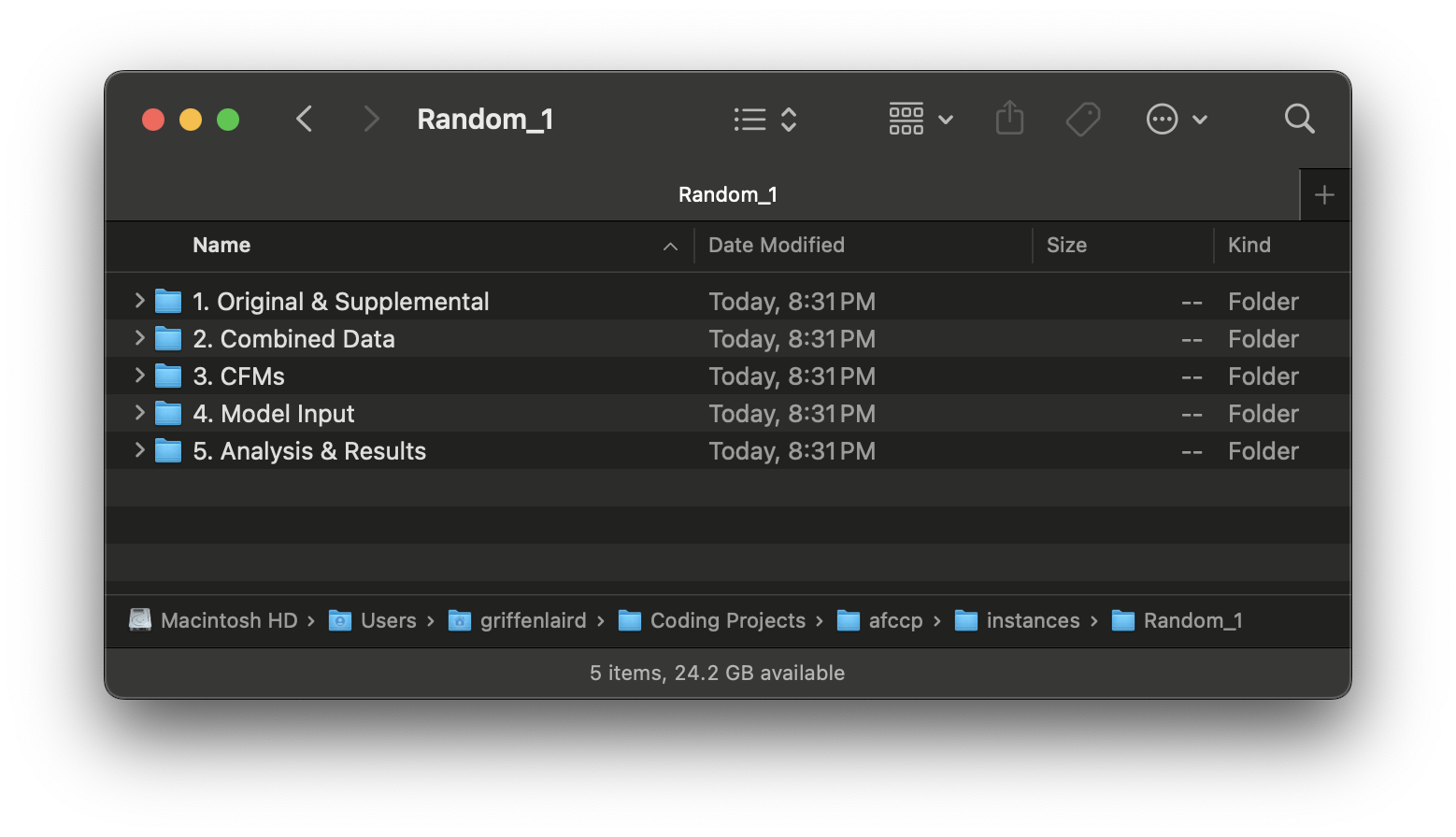
The first 3 all relate to the pre-processing "phases" that AFPC/DSYA goes through to get the data into the problem instance format and are irrelevant for this tutorial. For a real class year of cadets/AFSCs, these 3 sub-folders will be filled with real data in order to get it into sub-folder "4. Model Input".
Since we've generated data, all of these parameters are located in this sub-folder:
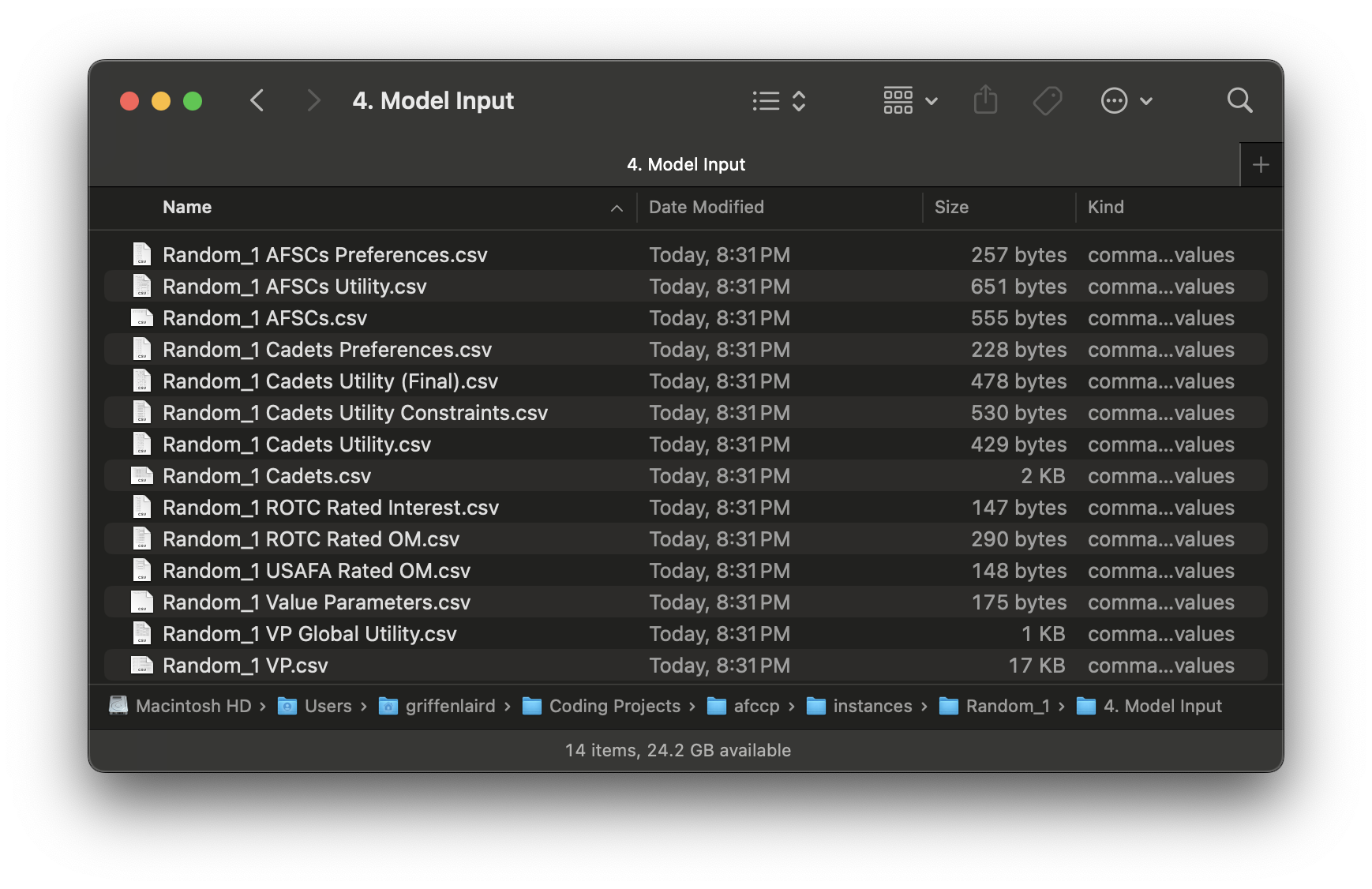
The files shown above, and which you should also have if you're following along, contain all the information stored in the data dictionaries "parameters" and "value_parameters". In a moment I will discuss what that data looks like and how it's stored in this dictionary structure. Lastly, let's re-import the "Random_1" problem instance:
Importing Data¶
To import data, it is very simple: specify the "data_name" of the instance you want to import. Here, we will import "Random_1":
# Import "Random_1" instance
instance = CadetCareerProblem('Random_1')
💻 Console Output
Importing 'Random_1' instance...
Instance 'Random_1' initialized.
At this point, we're ready to dive into the different data elements and structures used within CadetCareerProblem.
📌 Summary¶
In this tutorial:
- We introduced the
datamodule withinafccp, which handles most of the parameter creation and manipulation logic. - We broke down the purpose of each submodule in
afccp.data:adjustments.py: for manipulating and validating parametersgeneration.py: for generating synthetic cadet/AFSC datapreferences.py: for managing preference matricesprocessing.py: for importing/exporting data filessupport.py: for CadetCareerProblem support functionsvalues.py: for creating and managing value parameters
- We explained the role of
mdl_p, the instance hyperparameter dictionary used across modules. - We demonstrated how to generate synthetic data using
CadetCareerProblem('Random', N=20, M=4, P=4). - We showed how to fix and export that generated data using
instance.fix_generated_data()andinstance.export_data(). - We visualized how that data is stored within the "instances" folder.
- We described how to import a saved problem instance using
CadetCareerProblem('Random_1').
You’re now ready to explore the different data elements and structures in Tutorial 3!